git를 설치하였다는 가정 이후 부터 설명을 진행한다. 이후에 툴 사용하는 방법도 설명하겠지만 git를 이해하기 위해서 command를 사용해 보는 것이 좋다. 우선 command 사용법을 익히고 툴 사용법을 살펴보자. (원격 저장소에 관한 주소는 하이브레인넷 부설연구소와 창원대학교 데이터베이스 연구실에서 실습을 하기 위한 목적으로 비공개 되어 있는 원격 저장소 입니다. 공개용 원격 저장소를 활용한 예제는 추가 적으로 포스팅 할 예정입니다. 원격 저장소를 제외한 예제들은 모두 동일하게 테스트 하실 수 있습니다.)1. 로컬 환경 설정
git는 리눅스 소스를 관리하기 위해서 나온만큼 리눅스 명령어와 매우 비슷하다. 윈도우즈 용 git 역시 git-sh를 사용해서 git 명령어를 그대로 사용할수 있고 리눅스 명령어를 상용할 수 있다.
우선 현재 설정된 목록을 출력해보자.
git config --list
기존에 git를 사용하던 사용자라면 다음과 비슷한 내용이 출력이 될 것이다.
(1) 사용자 정보 추가
git를 사용하기 위해서는 기본적으로 이름과 이메일 주소가 필요하다.
git config --global user.name "{이름}"
git config --global user.email "{이메일주소}"
(2) 칼라 설정
터미널에서 git명령에 color를 지정하는 것이 좋다. 그래야 나중에 변환된 소스가 추가,수정,삭제 되었는지를 쉽게 판별할 수 있기 때문이다. --global 옵션은 전역으로 설정한다는 뜻이다.
git config --global color.ui "auto"
(3) 인코딩 설정
맥이나 리눅스에서는 디폴트가 UTF-8이기 때문에 이 설정이 필요 없지만 윈도우 환경일 경우에는 cp949로 인코딩을 설정해줘야 한글이 깨어지지 않는다.
git config --global i18n.commitEncoding cp949
git config --global i18n.logOutputEncoding cp949
2. 인증
(1) 로컬 PC에서 SSH-Key 생성
git를 사용하기 위해서는 RSA로 된 공개키가 필요하다. 이때 RSA 공개키는 ssh 공개키로 인증하는 방법과 같으며 ssh-keygen을 이용하여 공개키를 생성한다. ssh의 공개키가 ~/.ssh 폴더 밑에 생긴다. 키를 생성할때 다른 경로로 지정할 수 있으나 통상 ~/.ssh 밑에 id_rsa.pub와 같이 생성이 된다.
ssh-keygen -t rsa
라고 물어보는데 특별한 경로를 지정하지 않을 때는 엔터를 치면 된다. 공개키가 생성되었는지 확인해보자.
cat ~/.ssh/id_rsa.pub
다음과 같이 공개키가 ssh-rsa로 만들어진 것을 확인할 수 있다. 이것을 이용해서 git-server에 접근할때 인증하는 공개키로 사용할 것이다.
ssh-rsa AAAAB3..........NP/iiw== Saltfactory@Saltfactory.local
윈도우 사용자일 경우 Git Bash 프로그램을 실행 시켜서 동일하게 게 사용하면 된다.
(2) git 호스팅 서비스나 git 서버에 SSH-key를 추가
https://git.hibrainapps.net 으로 접근하면 초청받은 사용자는 git 서비스를 받을 수 있는데 dashboard 메뉴에 들어 가면 다음과 같이 Manage SSH Keys라는 메뉴에서 생성한 공개키를 등록할 수 있다. 인증받지 않은 PC에서 작업을하거나 ssh-keygen으로 다시 키를 생성했다면 Manage SSH Keys에서 키를 새로 등록해줘야한다. ( 하이브레인넷 부설 연구소 팀과 창원대학교 데이터베이스 연구실 학부생 및 대학원 생은
@hibrainapps 나
@saltfactory 트위터로 DM으로 요청하시거나 apps@hibrain.net 으로 메일주소와 이름으로 요청하시면 바로 git 서버 계정 발급해드립니다.)
Manage SSH Keys 메뉴를 눌러보면 다음과 같이 SSH Key를 관리하고 있는 것을 볼수 있다.
새로 SSH Key를 등록하기 이해서는 Add SSH key를 누른다. 그리고 다음과 같이 생성한 ssh-rsa 키를 복사해서 붙여 넣고 Save를 누른다.
이제 git 서버에서 관리자가 권한을 열어주면 원격 저장소에 소스코드를 fetch, pull, push를 할 수 있게 된다.
3. git 프로젝트 만들기
(1) 저장소 생성
프로젝트가 진행되거나 소스를 포함할 디렉토리를 하나 만든다. 우리는 이것을 하나의 저장소로 생각할 것이다. SimpleProject라는 폴더를 만들고 난후 SimpleProject 폴더 안으로 이동해서 git init을 사용하여 초기화 한다. 간단하게 git 저장소가 생긴 것이다.
mkdir SimpleProject
cd SimpleProject
git init
(2) 파일 추가
git 는 관례적으로 git 저장소 바로 밑에 README 파일을 만든다. 이것이 이후에 git 호스팅 서비스에서 소개글이나 도움말 기능을 하게 된다.
touch README
(3) 저장소에 파일 추가
이제부터 우리는 파일을 추적하면서 소스의 이력을 관리할 것이다. git에서는 이 작업을 하기 위해서 두단계 과정이 있는데 add와 commit이라는 기능이다.
추가한 파일을 stage 영역에 올리기 위해서 git add를 상용하고 이것을 commit 객체로 만들기 위해서 git commit을 사용한다. 다시 말해서 README 파일을 실제로 이력을 관리하기 위해서 이 두가지 과정을 거쳐야 한다는 것이다.
git add README
git add README 를 한후 stage 의 상태를 확인하면 다음과 같이 stage에 새로운 파일 README가 추가 되었다는 것을 알 수 있다.
git commit -m "{커밋 내용, 파일의 수정 내용을 상세하게 적어둔다}"
커밋을 진행하고 나면 stage에 있던 내용을 커밋 객체로 만들고 stage 영역을 다시 비우게 된다.
변경된 이력을 살펴보기 위해서는 git log를 이용해서 살펴볼 수 있다.
git log
이때 commit 객체는 Hash 값을 가지고 있는데 이것은 두명이 동시에 코드를 작성하다 충돌이 났을때 리비전할때 상요한다. 이 해시값이 중복되면 commit 구별이 어려워지지만 SHA-1해시로 만들경우 동일한 값이 나울 경우는 9,223,372,036,854,775,808분의 1의 확률을 가지고 있다.
git에서 코드는 세곳에 저장한다.
1. 파일을 작업할때 직접 이용하는 작업 트리
2. 스테이징 (stage)라는 인덱스이며 이 공간은 작업 트리와 저장소 사이의 buffer이다.
3. 최종 코드가 저장되는 저장소이다.
이 세가지를 기억하면서 간단한 query를 포함한 demo.sql 파일을 저장소 내에서 추가해보자.
echo "select * from student;" > demo.sql
demo.sql 라는 파일이 작업 트리에 추가되면서 git의 스테이징에 추적할 수 있는 파일이 하나 있으니 추가하라고 메세지가 나온다. 빨갛게 표시된 것은 아직 스테이징(stage)영역에 들어가지 않은 작업 트리에만 있는 것이다. 이것을 rm -rf로 삭제하면 작업트리에서 사라지기 때문에 git 스테이징 영역과 저장소에 전혀 반영되지 않는다.
git add demo.sql
git add를 해서 stage 영역에 추가를 하였다.
(4) 파일 삭제
여기서 만약 스테이징 영여게서 삭제하려면 다음과 같이 하면 된다.
git rm --cached demo.sql
이것은 스태이징 영역에 인덱스되어진 것을 버퍼에서 내려서 작업 트리에만 존재하게 하는것이다.
demo.sql을 아직 스테이징 영역에 올리지 말고 README 파일을 수정해보자.
echo "하이브레인넷 부설연구소 GIT 세미나" > README
앞에 demo.sql 파일이 추가된 것과 작업트리 영역에서 README 파일이 변경된 것을 알 수 있다. 우리는 이 변경된 두가지 모두를 한번에 스테이징 영역에 올릴고 싶다. 이렇게 여러개의 파일을 한번에 올릴 경우는 "." 을 상용하면 된다.
git add .
READE 파일이 변경된 것과 demo.sql이 새로 추가된 것을 스태이징 영역에 반영하였다.
이제 git commit을 저장소에 파일을 저장하자.
git commit -m "README 파일 수정과 demo.sql 파일 추가"
(5) 파일 이름 변경
파일 삭제를 git rm으로 하듯 파일 이름 변경은 git mv로 하면 된다.
git mv demo.sql sample.sql
(6) 다른점 찾기
git는 코드를 세가지 저장 공간을 갖는다고 했다. (작업트리, 스태이징, 저장소) 현재 변경한 파일이 이들 사이에 어떻게 변경되었지 확인하는 방법을 알아보자.
README 파일 열어서 다음과 같이 수정해보자.
vi README
2012년 1월 20일 GIT 세미나
주체 : 하이브레인넷 부설연구소
대상 : 하이브레인넷 부설연구소, 데이터베이스 연구실
git diff를 이용해서 저장공간의 차이점을 비교할 수 있다. 이때 git diff는 작업트리와 스태이징 사이의 차이점을 비교하고, git diff --cahced는 스태이징 영역과 저장소 사이의 차이점을 비교한다. 마지막으로 HEAD는 작업트리, 스태이징, 저장소의 변경사항을 모두 보여준다.
git add .
이 때 HEAD는 현재 작업중인 브랜치에서 가장 최신의 커밋을 나타내는 일종의 포인트와 같은 키워드이다. branch 를 이야기 할때 다시 언급하겠다.
(7) 추적하지 않을 파일 설정하기
git를 무엇을 관리할 것인지 물어보면 대답은 모든 것을 다 관리한다고 생각하면 된다. 실제 git 파일이 BLOB으로 저장되어 어떠한 파일이든지 추적관리를 할 수 있다. 그런데 반대로 반드시 하지 않아야하는 파일들이 있다. 예를 들어서 보안에 민감한 파일이나 툴 환경 설정에 관련된 파일 등 작업 폴더안에서 어떤 특수한 파일을 제외하고 싶을때 git에서는 .gitighore라는파일을 만들어서 그 안에 제외할 패턴을 넣어주면 된다.
앞에서 만든 공개키와 같은 것은 노출되면 보안상 좋지가 않다. 그렇기 때문에 .pub로 끝나는 파일은 git 관리에서 제외 시키고 싶을 경우 다음과 같이하면 된다.
echo "*.pub" > .gitingnore
4. branch 사용
git의 젤 중요한 기능중에 하나가 branch를 사용하는 것이다.
프로그램을 구현할때 항상 요구사항이 변경되는 것 때문에 코드가 여러가지 형태로 각각 소스를 관리할 필요가 있게 된다. 특히 여러가지 업무를 동시에 할때 이 branch라는 기능은 매우 명확하고 편리하게 개발 할 수 있게 만들어준다. branch를 언제 분기 시킬것을 결정하기는 어려운 문제이다.
"Git 분산 서버 관리 시스템"이라는 책에서는 다음과 같은 경우 branch를 만들라고 말하고 있다.
첫째, 실험적인 변경 사항이 일아날 때
둘째, 새로운 기능이 추가 될 때
셋째, 버그 수정을 할 때
현재 저장소에 branch들을 확이하려면 다음과 같이하면 확인할 수 있다.
git branch
(1) branch 생성
새로운 branch를 생성하기 이해서는 간단하게 git branch {브랜치명}으로 만들면 된다.
git branch dev-1.0M1
이렇게 생성한 branch 와 master 간에 이동을 할 수 있는데 이때 checkout을 이용해서 서로 branch를 변경할 수 있다.
git checkout dev-1.0M1
dev-1.0M1 브랜치에서 sample.sql를 수정해보자.
select s.name, d.name from student s, department d where s.deptno = d.deptno;
그리고 파일을 하나 추가하자
touch index.html
그리고 모두 commit을 한다.
git add . ; git commit -m "쿼리 추가, index.html 파일 추가"
현재 HEAD가 dev-1.0M1 브랜치를 가르키로 있을 때이다.
HEAD가 master 브랜치를 가르키게 할 경우 다음과 같아 진다. dev-1.0M1에서 추가한 index.hml 파일은 보이지 않고 sample.sql에 추가한 쿼리문도 보이지 않게 된다.
두 branch간의 차이점을 git diff로 확인 할 수 있다.
git diff dev-1.0M1
(2) branch 삭제
현재 HEAD가 master인데 우리는 dev-1.0M2라는 branch를 하나 더 만들고 dev-1.0M1 branch를 삭제하고 싶다.
git checkout -tb "dev-1.0M2"
git branch -d "dev-1.0M1"
하지만 에러가 발생한다. 왜냐면 master에서 분기되어져 나와서 작업을 진행했는데 변경된것을 무시하고 삭제를 하려고하기 때문이다. 그래서 강제로 삭제하고 싶으면 git branch -D 옵션을 사용해서 강제로 삭제하라고 한다.
우리는 새로 만든 dev-1.0M2에다가 dev-1.0M1을 합치고 난 후 dev-1.0M1 브랜치를 삭제 하기로 한다. 현재 HEAD가 가리키는 것은 dev-1.0M2 이다. 현재 branch에서다 dev-1.0M1의 내용을 merge하기 위해서 다음과 같이 한다.
git merge dev-1.0M1
이제 다시 dev-1.0M1을 삭제해보자
git branch -d "dev-1.0M1"
4. 원격지에 있는 저장소 사용
https://git.hibrainapps.net/hbn-tutorials 사이트에 가면 테스트할 저장소가 다음과 같이 있을 것이다 (이 저장소 주소는 접근 권한을 받은 연구소와 연구실 팀만 사용 가능합니다. 테스트를 위해 다른 원격지 저장소 URI를 사용하셔도 상관 없습니다.)
git@git.hibrainapps.net:hbn-tutorials/java-tutorial.git
(1) 원격지 저장소 로컬로 복제하기
원격 저장소에 있는것을 복제하기 위해서는 git clone을 사용한다.
cd ..
git clone git@git.hibrainapps.net:hbn-tutorials/java-tutorial.git
우리는 각자 새로운 branch를 만들어서 작업을 한다고 가정하자. 중복되지 않는 branch를 만들기 위해서 "{git사이트 계정}-dev-1.0.M1" 이라고 branch 이름을 만들자.
git checkout -b "saltfactory-dev-1.0M1"
(2) IDE와 git 상호 연동
이제 IntelliJ로 이 프로젝트 파일을 열어보자.
IntelliJ를 시작하면 프로젝트를 선택하는 다이얼로가 나타나는데 우리는 원격 저장소에서 git로 관리되는 IntelliJ 소스 파일을 복제 하였고 새로운 개발을 하기 위해서 saltfactory-dev-1.0M1 이라는 branch도 만들었다. 그렇게 때문에 이미 IntelliJ 포르젝트가 존재하는 이유로 존재하는 소스를 가지고 프로젝트를 생성한다고 체크한다.
우리가 clone 받은 소스는 java-tutorial 이라는 git 폴더이고 그 안에 IntelliJ로 만든 프로젝트로 폴더 SimpleJavaProject가 있는데 이 것을 선택하도록 한다.
이제 IntelliJ가 열리면서 모든 프로젝트가 세팅되고 소스가 보이게 된다.
우리는 단지 저장소를 복사하고 branch를 추가하고 프로젝트를 열었을 뿐인데 프로젝트 메니저가 샘플 소스 코드를 만들어 주었다는 것을 확인 할 수 있다.
IntelliJ에서 git를 사용하기 위해서 VCS 메뉴에서 Enable Version Controller을 활성화 해줘야한다.
(1)맥 용 IntelliJ의 VCS 버전 컨트롤러 활성화
(2) 윈도우 용 IntelliJ의 VCS 버전 컨트롤러 활성화
예제 소스는 IntelliJ와 git을 이용해서 Java와 SQL을 개발할 수 있는 예제이다. 데이터베이스에 커넥션하여 SQL을 실행하기 위해서는 다음과 같이 새로은 커넥션을 만든다. (IntelliJ의 Database Navigator 플러그인을 설치해야 .sql 파일에서 바로 쿼리를 실행할 수 있다. 디폴트로는 이 플러그인이 빠져 있기 때문에 Database Navigator 플러그 인을 설치하길 권장한다.)
이때 데이터베이스에 커넥션하기 위해서 JDBC 드라이버를 사용한다. 오라클 사이트에서 Oracle 10g/11g Client를 다운 받아서 사용하면 된다. JDBC 드라이버만 있으면 가능하기 때문에 Oracle 10g/11g Instant Client를 다운 받아도 상관 없다. instant client는 소스 컴파일 과정이 필요없기 때문에 간단히 라이브러리와 드리아버를 사용할 수 있다. 이 예제는 instant client를 이용해서 만들어져 있다. Driver library에 이제 JDBC 라이브러리 경로를 입력하면 된다. 예를 들어 /Projects/Servers/Oracle/instantclient/instantclient_10_2/ojdbc14.jar 과 같이 입력한다. 다음은 Driver를 선택할 수 있는데 oracle.jdbc.driver.OracleDriver와 oracle.jdbc.OracleDriver를 선택할 수 있는데 oracle.jdbc.driver.OracleDriver를 선택한다. 다음은 URL은 jdbc의 thin 모드 커넥션을 이용할 것이다. 간단한 테스트 과정이기 때문에 개발용으로 thin 모드로 연결해서 사용하면 충분하다.
jdbc:oracle:thin@{오라클서버호스트}/{오라클SID} 모든 설정후 test 버턴을 클릭해서 연결 상태를 확인한다. 만약 연결 상태가 양호하면 다음과 같은 메세지를 볼 수 있다.
이제 .sql 파일에서 특정 statement를 선택해서 Run을 시키면 그 결과가 table 구조로 다음과 같이 바로 확인이 될 것이다. 이제 query를 터미널에서 열어서 vi 로 작성하거나 하지 않고 IDE를 이용해서 좀더 효율적이고 효과적으로 개발할 수 있게 되었다.
또한 Database Navigator 플러그인을 사용하면 코드 어시스턴스를 사용할 수 있게 된다. 테이블이나 컬럼을 코드 어시스턴스를 이용해서 쉽게 코드를 완성할 수 있게 된다.
students.sql 파일을 열어서 다음 코드를 추가하였다.
select * from student s, department d
where s.deptno = d.deptno;
git로 소스를 관리하고 있는 이 저장소에서 파일이 변경 되어 지면 변경된 파일은 다음과 같이 파란색으로 변경이 된다. 만약 새로운 파일이 추가가 되면 녹색이 되고, git 스테이징 영역에서 삭제되거나 제외될 경우에는 빨간색으로 나타난다.
변경된 student.sql 파일 위에서 오른쪽 마우스를 클릭해서 컨텍스트 메뉴를 열어서 Git 메뉴중에서 commit 메뉴를 선택해보자. 우리가 앞에서 같이 했던 git commit -m 이라는 명령어 대신에 마우스를 이용해서 이 작업을 대신하는 거시다. comment에 메세지를 넣고 커밋 후에 바로 원격지에 소스를 push 할 것인지를 선택하는 commit 버턴이 있다. commit은 단순히 로컬에 복제한 소스 저장소에 commit을 하는 것이고 commit and push는 commit을 완료하고 원격 저장소에 변경된 로컬의 commit을 원격지에 push하는 것을 의미한다. (create patch를 unix에서 자주 자용하는 patch 파일을 만드는 것이다. 이것은 git를 사용하지 않는 곳이라도 patch 파일을 만들어서 소스를 변경 사항을 적용 시킬때 사용할 수 있다.)
단순히 로컬 저장소에 commit만 완료해 보자. Commit을 선택한다. 그리고 student.sql 파일에 오른쪽 마우스를 클릭해서 컨텍스트 메뉴를 열어서 Git > Show History 메뉴를 선택해보자. 그러면 방금 커밋한 이력 정보를 확인 할 수 있게 된다.
소스를 다시 돌리기 위해서는 이 이력정로를 더블클릭해보자.
녹색으로 select 문장 하나가 추가된 것을 확인 할 수 있다. 이제 이 코드 이전으로 돌아가기 위해서 show history 이력에서 이 변경 바로 전의 commit 위에서 마우스 오른쪽을 클릭한다. 해시 값은 c89ddab 이다. 그리고 Get을 선택한다.
이 작업은 이젠 commit 시점으로 코드를 변경한 작업을 한 것이다. 소스코드들은 이전 시점으로 돌아가게 되고 변경된 파일은 다시 파란색으로 표시가 된다. 이렇게 변경된 것을 다시 반영하려면 commit을 하면 된다.
이번에는 commit과 동시에 push를 해보자. 로컬 저장소에 commit이 완료 됨과 동시에 push를 위한 다이얼로그가 하나 더 나타나는데 이데 puch할 branch를 선택할 수 있고 커멧 메세지를 다시 확인 할 수 도 있다. 보통 revert 시키는 작업은 commit 해시 값을 입력해주는 것이 좋다.
이제 원격지에 push를 하기 위해서 인증을 한다. git 서버에서 인증받았던 비밀번호를 입력하면 된다. Remember the passphrase를 체크하면 인증해시 값이나 비밀번호가 변경되기 전까지는 묵시적으로 자동인증이 가능하다.
이렇게 push된 소스는 http://git.hibrainapps.net 에서 웹으로 확인이 가능하다. 이 예제에서 사용한 저장소는 https://git.hibrainapps.net/hbn-tutorials/java-tutorial 과 같다. 그리고 방금 commit 한 메세지와 blame 정보를 확인 할 수 있다.

5. 요약
이 포스트는 git를 사용해서 로컬 저장소를 활용하는 방법을 소개하고 있다. 그리고 git.hibrainapps.net의 원격 저장소에서 저장소를 복제하고 IntelliJ를 이용해서 git를 사용하는 방법을 간단히 소개하고 있다. 이 포스트는 "하이브레인넷 부설연구소"와 "창원대학교 데이터베이스 연구실"의 세미나 목적으로 만들어진 포스트로 비공개 원격 저장소를 사용했지만 공개용 원격 저장소를 사용할 경우도 방법은 동일하다. 다만 원격 저장소의 주소만 다르게 사용하면 된다. 또한 공개용 원격저장소를 이용하는 방법은 이후에 다른 공개 튜토리얼을 작성하면서 사용 예제를 같이 포스팅 할 예정이다. git는 중앙 집중식으로 버전을 관리하던 SVN과 달리 중앙 집중식 뿐만 아니라 로컬에서도 코드를 관리할 수 있다는 것을 보았다. 또한 git는 작업트리 영역과 스테이징 영역 그리고 저장소 영역을 나누어서 코드를 관리하는 것도 설명했다. 또한 터미널에서 사용하던 명령어를 IDE와 연동해서 프로그램을 작성하면서 바로 git를 사용하는 방법도 살펴보았다. 이렇게 git의 실전 사용법 - 기본편을 살펴보았다.
6. 결론
우리는 프로젝트를 진행하면서 코드의 관리를 위해서 버전관리시스템을 이용해왔다. 기존에는 SVN을 사용했으나 이는 서버중심의 중앙 집중식 버전 관리 시스템이기 때문에 로컬에서 버전 관리를 할 수 없었던 반면에 git를 이용하면 로컬 작업도 버전 관리가 가능하게 되었다. 이러한 이유로 네트워크가 없는 상황에서도 작업을 지속적으로 버전 관리를 하면서 할 수 있게 된다는 것을 알게 되었다. 또한 git는 branch 기능을 사용해서 여러가지 소스를 병렬작업 할 수 있는 기능도 살펴보았다. 이 branch를 이용해서 다양한 버전으로 코드를 테스트하거나 프로젝트의 개발에 테스트와 소스코드의 분기를 할용해서 코드의 품질을 높이는 방법도 살펴보았다. 기본편에서는 원격저장소를 사용하는 설명이 세미나에서는 이루어지지 않았는데 다음 세미나에서 원격저장소를 사용해서 좀더 공동작업하는 방법과 분산버전 관리하는 방법에 대해서 실전편으로 살펴볼 에정이다. git를 사용해서 좀더 고품질의 소스코드를 만들수 있고, 분산버전을 활용하고, 공동 작업을 효율적으로 효과적으로 할 수 있게 되기를 바래본다.
git를 윈도우 환경에서 DA#과 함께 이용하여 sql을 개발하는 방법과 IDE를 이용하여 웹 프로젝트, 모바일 프로젝트를 개발하는 내용을 git 실전편에서 계속될 예정입니다.
작성자 : 하이브레인넷 부설연구소, 송성광 개발 연구원 (
@saltfactory )
 클래스 표기법에 스테레오 타입(Stereo-Type)을 붙일 수 있는데, 스테레오 타입이란 UML의 한정된 모델 요소를 가지고 새로운 어휘를 표현하기 위한 방법입니다. 메소드 명 위에 아래의 예처럼 스테레오 타입을 붙이면 해당 메소드는 생성자라는 것을 표기하는 것입니다.
클래스 표기법에 스테레오 타입(Stereo-Type)을 붙일 수 있는데, 스테레오 타입이란 UML의 한정된 모델 요소를 가지고 새로운 어휘를 표현하기 위한 방법입니다. 메소드 명 위에 아래의 예처럼 스테레오 타입을 붙이면 해당 메소드는 생성자라는 것을 표기하는 것입니다.
 예제는 프로그래머 클래스가 사용하는 쪽이고 컴퓨터 클래스가 사용되는 쪽입니다. 사용되는 클래스가 사용하는 클래스의 메소드 파라미터로 사용되는 경우, 사용되는 클래스가 사용하는 클래스의 메소드 로컬 변수로 사용되는 경우, 사용되는 클래스가 사용하는 클래스의 전역 변수로 사용되는 경우입니다.
의존 관계는 has a 관계를 가지는 클래스들 간에 변수나, 메소드의 파라미터의 사용을 가지는 클래스의 관계를 표시합니다.
예제는 프로그래머 클래스가 사용하는 쪽이고 컴퓨터 클래스가 사용되는 쪽입니다. 사용되는 클래스가 사용하는 클래스의 메소드 파라미터로 사용되는 경우, 사용되는 클래스가 사용하는 클래스의 메소드 로컬 변수로 사용되는 경우, 사용되는 클래스가 사용하는 클래스의 전역 변수로 사용되는 경우입니다.
의존 관계는 has a 관계를 가지는 클래스들 간에 변수나, 메소드의 파라미터의 사용을 가지는 클래스의 관계를 표시합니다.
 추상클래스(Abstract) 는 이탤릭체나 스테레오 타입으로 표시합니다.
추상클래스(Abstract) 는 이탤릭체나 스테레오 타입으로 표시합니다.
 [인스턴스의 표기법]
[인스턴스의 표기법]




















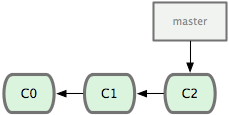
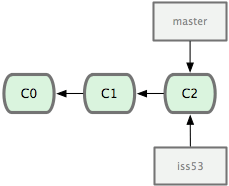
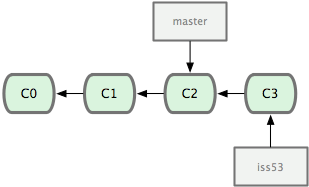
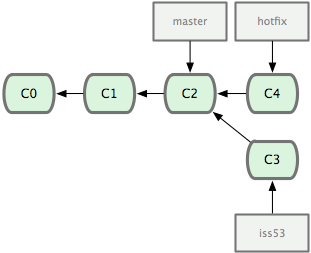
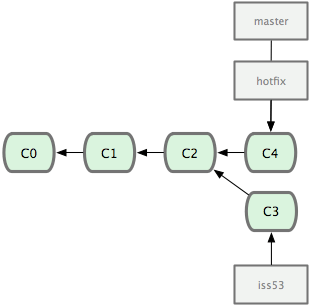
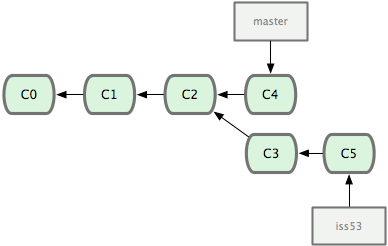
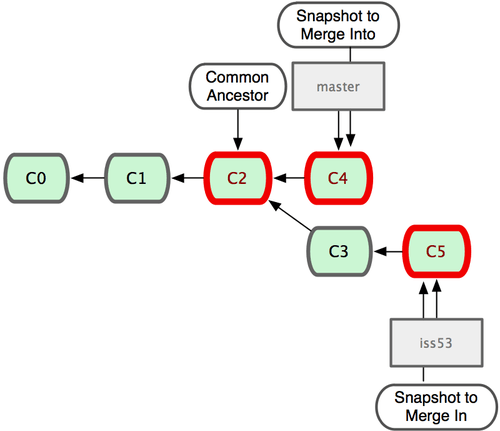
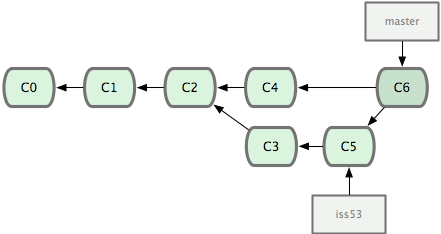
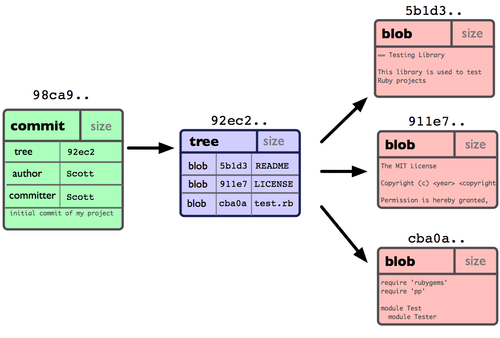 그림 3-1 저장소의 커밋 데이터
다시 파일을 수정하고 커밋하면 이전 커밋이 무엇인지도 저장한다. 커밋을 두 번 더 하면 그림 3-2과 같이 저장된다.
그림 3-1 저장소의 커밋 데이터
다시 파일을 수정하고 커밋하면 이전 커밋이 무엇인지도 저장한다. 커밋을 두 번 더 하면 그림 3-2과 같이 저장된다.
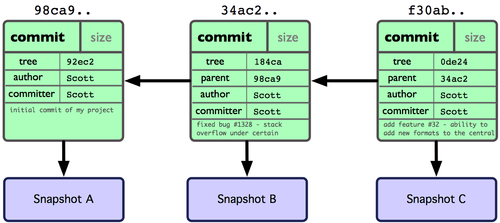 그림 3-2 Git 커밋의 개체 데이터
Git의 브랜치는 커밋 사이를 가볍게 이동할 수 있는 어떤 포인터 같은 것이다. 기본적으로 Git은
그림 3-2 Git 커밋의 개체 데이터
Git의 브랜치는 커밋 사이를 가볍게 이동할 수 있는 어떤 포인터 같은 것이다. 기본적으로 Git은 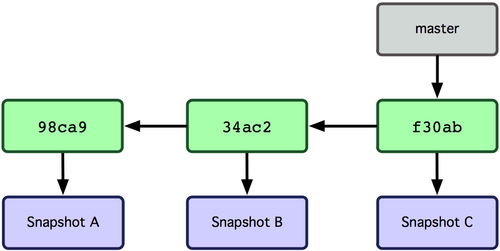 그림 3-3 가장 최근 커밋 정보를 가리키는 브랜치
브랜치를 하나 새로 만들면 어떨까? 브랜치를 하나 만들어서 놀자. 다음과 같이
그림 3-3 가장 최근 커밋 정보를 가리키는 브랜치
브랜치를 하나 새로 만들면 어떨까? 브랜치를 하나 만들어서 놀자. 다음과 같이 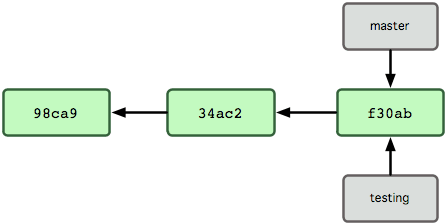 그림 3-4 커밋 개체를 가리키는 두 브랜치
지금 작업 중인 브랜치가 무엇인지 Git은 어떻게 파악할까? 다른 버전 관리 시스템과는 달리 Git은 'HEAD'라는 특수한 포인터가 있다. 이 포인터는 지금 작업하는 로컬 브랜치를 가리킨다. 브랜치를 새로 만들었지만, Git은 아직 master 브랜치를 가리키고 있다.
그림 3-4 커밋 개체를 가리키는 두 브랜치
지금 작업 중인 브랜치가 무엇인지 Git은 어떻게 파악할까? 다른 버전 관리 시스템과는 달리 Git은 'HEAD'라는 특수한 포인터가 있다. 이 포인터는 지금 작업하는 로컬 브랜치를 가리킨다. 브랜치를 새로 만들었지만, Git은 아직 master 브랜치를 가리키고 있다. 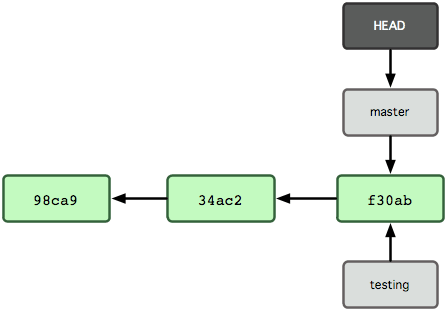 그림 3-5 HEAD는 현재 작업 중인 브랜치를 가리킴
그림 3-5 HEAD는 현재 작업 중인 브랜치를 가리킴
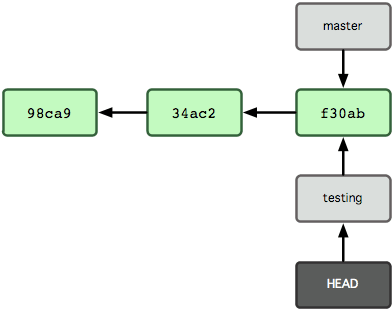 그림 3-6 HEAD는 옮겨간 다른 브랜치를 가리킨다
자, 이제 핵심이 보일 거다! 커밋을 새로 한 번 해보면:
그림 3-6 HEAD는 옮겨간 다른 브랜치를 가리킨다
자, 이제 핵심이 보일 거다! 커밋을 새로 한 번 해보면:
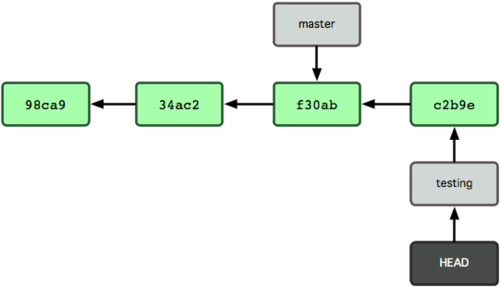 그림 3-7 HEAD가 가리키는 testing 브랜치가 새 커밋을 가리킨다
이 부분이 흥미롭다. 새로 커밋해서 testing 브랜치는 앞으로 이동했다. 하지만,
그림 3-7 HEAD가 가리키는 testing 브랜치가 새 커밋을 가리킨다
이 부분이 흥미롭다. 새로 커밋해서 testing 브랜치는 앞으로 이동했다. 하지만, 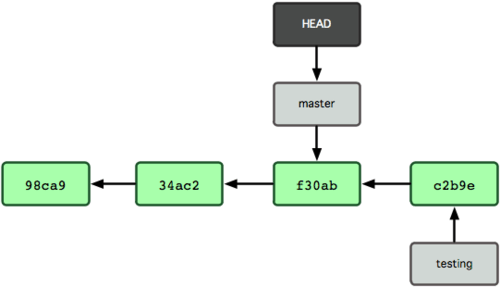 그림 3-8 HEAD가 Checkout한 브랜치로 이동함
방금 실행한 명령이 한 일은 두 가지다. master 브랜치가 가리키는 커밋을 HEAD가 가리키게 하고 워킹 디렉토리의 파일도 그 시점으로 되돌려 놓았다. 앞으로 커밋을 하면 다른 브랜치의 작업들과 별개로 진행되기 때문에 testing 브랜치에서 임시로 작업하고 원래 master 브랜치로 돌아와서 하던 일을 계속할 수 있다.
파일을 수정하고 다시 커밋을 해보자:
그림 3-8 HEAD가 Checkout한 브랜치로 이동함
방금 실행한 명령이 한 일은 두 가지다. master 브랜치가 가리키는 커밋을 HEAD가 가리키게 하고 워킹 디렉토리의 파일도 그 시점으로 되돌려 놓았다. 앞으로 커밋을 하면 다른 브랜치의 작업들과 별개로 진행되기 때문에 testing 브랜치에서 임시로 작업하고 원래 master 브랜치로 돌아와서 하던 일을 계속할 수 있다.
파일을 수정하고 다시 커밋을 해보자:
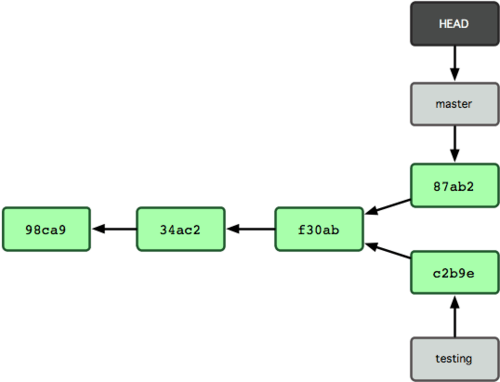 그림 3-9 브랜치 히스토리가 서로 독립적임
실제로 Git의 브랜치는 어떤 한 커밋을 가리키는 40글자의 SHA-1 체크섬 파일에 불과하기 때문에 만들기도 쉽고 지우기도 쉽다. 새로 브랜치를 하나 만드는 것은 41바이트 크기의 파일을(40자와 줄 바꿈 문자) 하나 만드는 것에 불과하다.
브랜치를 만들어야 하면 프로젝트를 통째로 복사해야 하는 다른 버전 관리 도구와 Git의 차이는 극명하다. 통째로 복사하는 작업은 프로젝트 크기에 따라 다르겠지만 수십 초에서 수십 분까지 걸린다. 그에 비해 Git은 순식간이다. 게다가 커밋을 할 때마다 이전 커밋의 정보를 저장하기 때문에 Merge할 때 어디서부터(Merge Base) 합쳐야 하는지 안다. 이런 특징은 개발자들이 수시로 브랜치를 만들어 사용하게 한다.
이제 왜 그렇게 브랜치를 수시로 만들고 사용해야 하는지 알아보자.
그림 3-9 브랜치 히스토리가 서로 독립적임
실제로 Git의 브랜치는 어떤 한 커밋을 가리키는 40글자의 SHA-1 체크섬 파일에 불과하기 때문에 만들기도 쉽고 지우기도 쉽다. 새로 브랜치를 하나 만드는 것은 41바이트 크기의 파일을(40자와 줄 바꿈 문자) 하나 만드는 것에 불과하다.
브랜치를 만들어야 하면 프로젝트를 통째로 복사해야 하는 다른 버전 관리 도구와 Git의 차이는 극명하다. 통째로 복사하는 작업은 프로젝트 크기에 따라 다르겠지만 수십 초에서 수십 분까지 걸린다. 그에 비해 Git은 순식간이다. 게다가 커밋을 할 때마다 이전 커밋의 정보를 저장하기 때문에 Merge할 때 어디서부터(Merge Base) 합쳐야 하는지 안다. 이런 특징은 개발자들이 수시로 브랜치를 만들어 사용하게 한다.
이제 왜 그렇게 브랜치를 수시로 만들고 사용해야 하는지 알아보자.


















































